

As the name refers, the quicksort is quick! If implemented well, it can perform two to three times faster than merge sort and heap sort. It is an efficient sorting algorithm developed by Tony Hoare in 1959 and published in 1961. It is a comparison sorting algorithm that acquires the Divide and Conquer approach.
This is the fourth day of the 30 days of algorithm series. In the last day, we discussed the merge sort. You can check that too!
How Quicksort works?
Quicksort is a Divide and Conquer approach. So, it has three phases. Divide, conquer and combine. In the merge sort, we saw the divide step hardly does anything. The combining step plays a real role to sort the list. But in quicksort, the real work happens in the divide step. We can say the combining step does absolutely nothing.
Consider we have the following array to sort. While sorting in ascending order we’ll try to get an overview of how the quicksort works.


Step 1: Divide
In this step at first, we choose a pivot. A pivot is any element from the array or subarray. In our discussion, we’ll always choose the rightmost element from a subarray as the pivot. After choosing the pivot we’ll rearrange the elements such a way that, all the elements that are less than or equal to the pivot are to its left and the elements that are greater than the pivot to its right. This procedure is called partitioning. After partitioning the pivot is in its final position.
How the partitioning works?
If the rightmost element is not chosen as the pivot, move it to the rightmost index. Now we start scanning the elements from the first index in left and from the next left element of pivot in right.

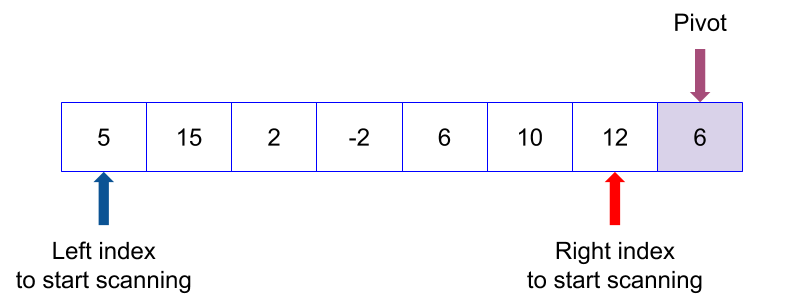
From left we look for the element that is greater than the pivot and from right we look for the element that is less than or equal to the pivot. When we find them, we swap the elements.

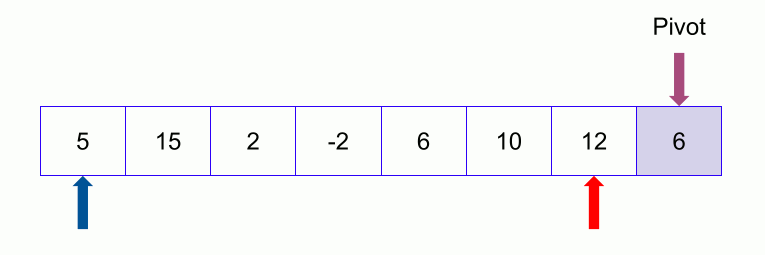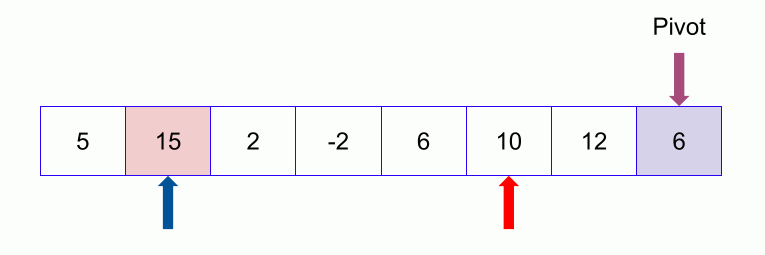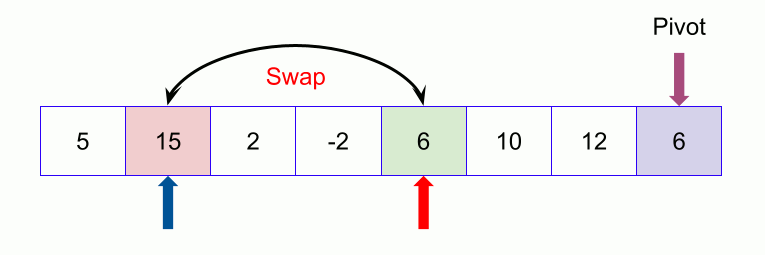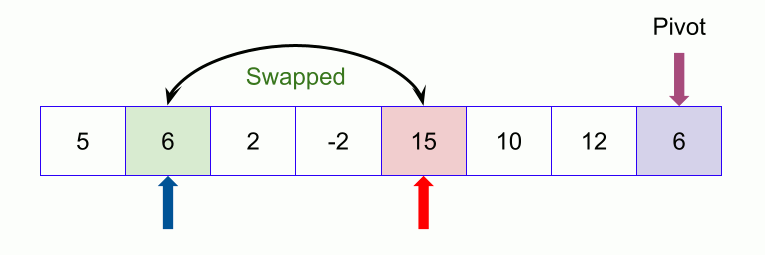
Now we keep continuing. If the index of the larger element than pivot ( say l ) is larger than the index of the smaller or equal element to pivot (say s) we stop. Now we swap the larger element ( at index l ) with the pivot.

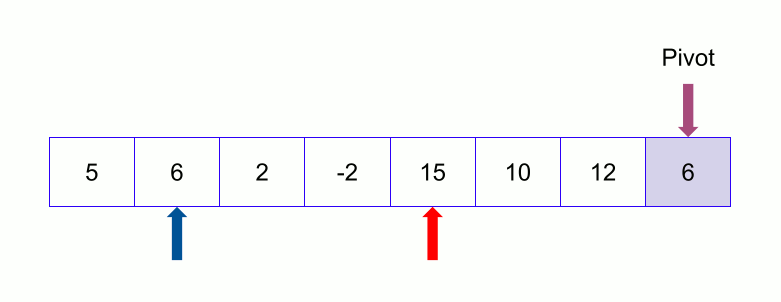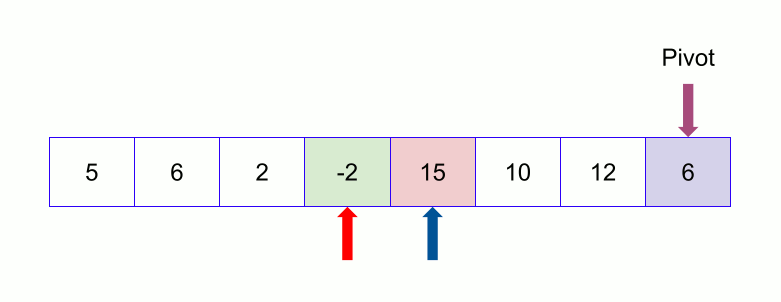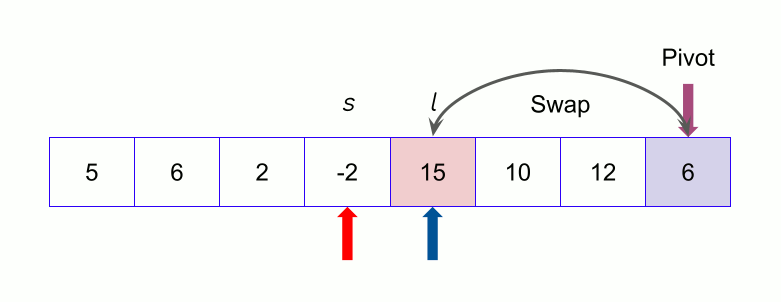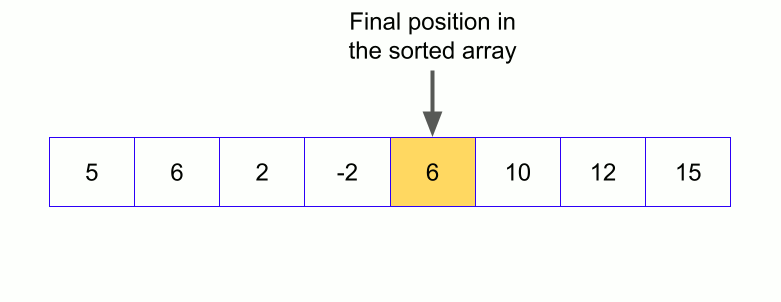
Now we divide the array into two subarrays except the pivot. One subarray contains the left part of the pivot and another one contains the right part of the pivot. With this, the divide phase finishes for this array.

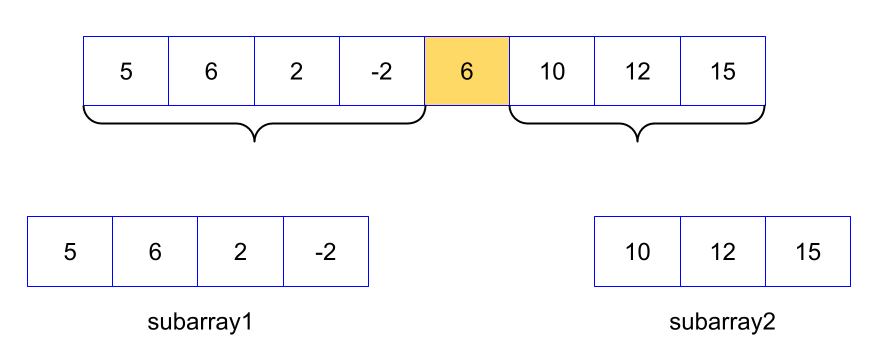
Step 2: Conquer
In this step, the subarrays will be recursively partitioned and sorted by fixing the position of the pivot of each subarray.


Step 3: Combining
This step doesn’t play a significant role in quicksort. At the end of conquering step the array is already sorted.
The Quicksort Algorithm
The pseudocode of the quicksort is as follows:
quickSort(A, low, high):
if low < high:
pivot_index := partition(A, low, high)
quickSort(A, low, pivot_index - 1)
quickSort(A, pivot_index + 1, high)
end if
end quickSort
The pseudocode for partitioning is as followed:
partition(A, low, high):
pivot := A[high]
pivotIndex := low
for i := low to high:
if A[i] < pivot:
swap A[pivotIndex] with A[i]
pivotIndex := pivotIndex + 1
end if
end for
swap A[pivotIndex] with A[high]
return pivotIndex
end partition
Implementation
A python implementation of quicksort is:
Complexity Analysis of Quicksort
There are three phases in quicksort i.e. divide and conquer approach – divide, conquer and combine. In the case of quicksort, the combining step hardly does anything. So the time is \(O(1)\). In the divide step, the partitioning takes \(O(n)\) time like the merging takes in merge sort. So in quicksort the dividing and combining take \(O(n)\) time together.
Now let’s come to the conquering phase. Let’s consider a case when the pivot is always the largest or smallest element and this is the worst case for quicksort. Each time the pivot will be at an end and will create an empty subarray and a \((n-1)\) sized subarray for an array of size \(n\). For a constant \(c\) the time of recursion will be \(cn\) and \(c(n-1)\) for the arrays of size \(n\) and \((n-1)\) respectively. Now the \((n-1)\)sized array will create a \((n-2)\) sized subarray and it will take \(c(n-2)\) time. This will go on until we reach the base case. It will be more clear from the following tree I found from Khan Academy.

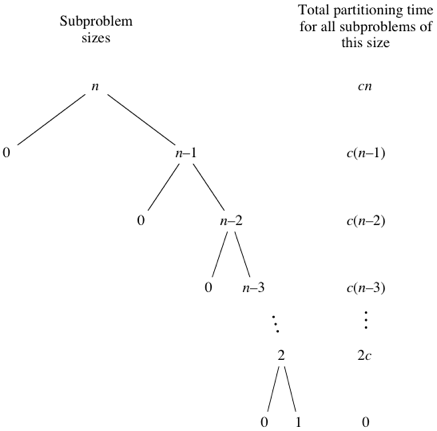
So the total time required is:
\(
\begin{equation}
\begin{split}
cn + c(n-1) + c(n-2) + … + 3c + 2c &= c\{n + (n-1) + (n-2) + … + 3 + 2\}\\
&= c(\frac{n(n+1)}{2}\ – 1)\\
&= c(\frac{1}{2}n^2 + \frac{1}{2}n\ – 1)
\end{split}
\end{equation}
\)
So, in worst case the time complexity of quick sort is \(O(n^2)\).
For average case lets consider we get a 3-to-1 division. If the array is of n size, we get a subarray of size \(3n/4\) and another subarray of \(n/4\). For simplicity we are considering the pivot is also in one of the subarrays. So the subproblem tree will look like the following tree from Khan Academy.

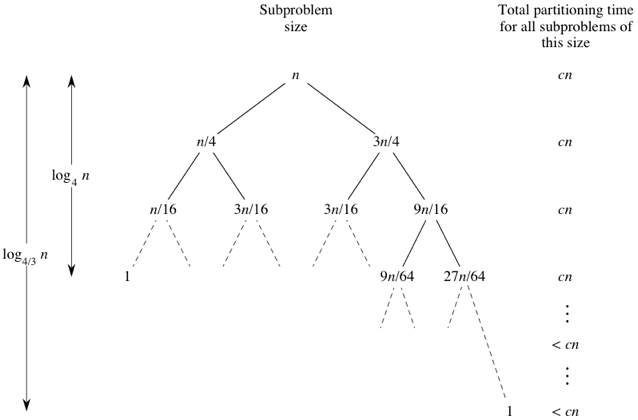
The smaller subarrays (of size \(n/4\)) are on left. So on the left side of the tree, we get the base case (subarray of size 1) early; to be exact after \(\log_4n\) levels. On the right side of the tree, we get the base case after \(\log_{\frac{4}{3}}n\) levels.
For first \(\log_4n\) levels, each level has subarrays of total size \(n\). So, requires time is \(cn\) for each of these levels. For the levels that are after \(\log_4n\) levels have less than \(n\) elements totally. So the required time is less than \(cn\) or at most \(cn\). So total time will be less than \(cn * \log_{4/3}n\) and that is \(O(n\log_{4/3}n)\).
Now, we know that \(\log_an = \frac{\log_bn}{\log_ba}\). So we can write:
\(
\begin{equation}
\begin{split}
\log_{4/3}n &= \frac{\log_2n}{\log_2\frac{4}{3}}\\
&= \frac{1}{\log_2\frac{4}{3}}\ * \log_2n\\
&= c_1 * \log_2n
\end{split}
\end{equation}
\)
Here \(c_1 = \frac{1}{\log_2\frac{4}{3}}\). So we can write on average case the running time is \(O(n\log_{2}n)\).
In best case the subarrays will be divided into two equal sized subarray. So for a array of size \(n\) there will be two subarrays of size \(n/2\). This will continue for other levels also and each level will have \(n\) elements in total. For for each level required time will be \(cn\) and there will be \(\log_2n\) levels. That indicates total time will be \(cn * \log_2n\), thus \(O(n\log_2n)\).
Time Complexities
- Worst case complexity: \(O(n^2)\)
If the pivot is always the largest or the lowest value then the worst case occurs. - Best case complexity: \(O(n\log_2n)\)
If the pivot is in the centre or near the centre of an array then the best case occurs. - Average case complexity: \(O(n\log_2n)\)
In other cases, an average case occurs.
Space complexity:
Space complexity is \(O(\log_2n)\).